閲覧してるページの選択テキストと一緒にタイトルとそのページのリンクを拾い上げるブックマークレットを作ってみました。ネタフルさんのネタリストみたいにあっちこっちの拾い読み記事書く時にあると便利かと思いまして。
ブックマークレットソース
作ったブックマークレットのソースは以下の通り。
javascript:
IE='v'=='v';
var selTxt;
if(IE){
selTxt = document.selection.createRange().text;
}else{
selTxt = window.getSelection().toString();
}
selTxt = selTxt.replace(/[nr]+/g,'nr');
var lastTxt = selTxt.slice(selTxt.length-1);
if(lastTxt == 'nr'){
selTxt = selTxt.slice(0,selTxt.length-2);
}
selTxt = '<a href="' +document.URL+ '">' + document.title+ '</a><blockquote><p>' + selTxt.replace('nr','</p><p>') + '</p></blockquote>';
prompt('',selTxt);
こちらのコードをブラウザのブックマークに適当に名前をつけて登録してください。
任意のページでテキストを反転選択してこのブックマークレットを実行すると、<a>タグのソースにページurl、テキストにページタイトル、それに続けて<blockquote>に内包された<p>タグが生成されダイアログに表示されます。元の選択テキストに改行を含む場合は改行ごとに複数の<p>タグが自動生成されます。
使い方サンプル
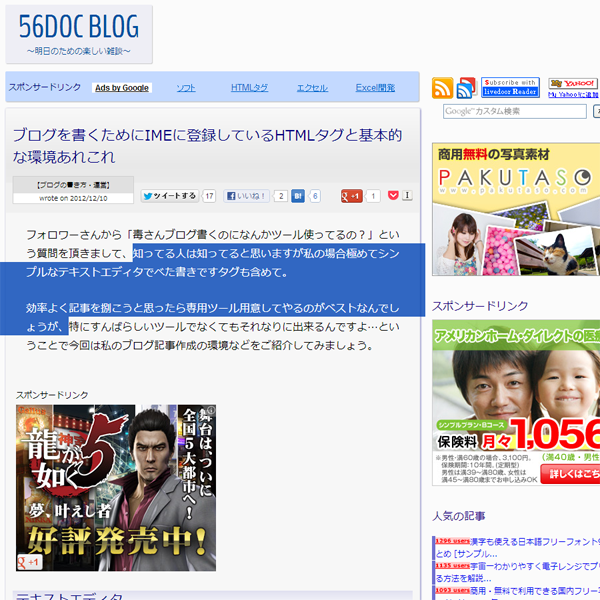
以下のページで実際にこのブックマークレットを実行してみます。
ブログを書くためにIMEに登録しているHTMLタグと基本的な環境あれこれ | 56docブログ
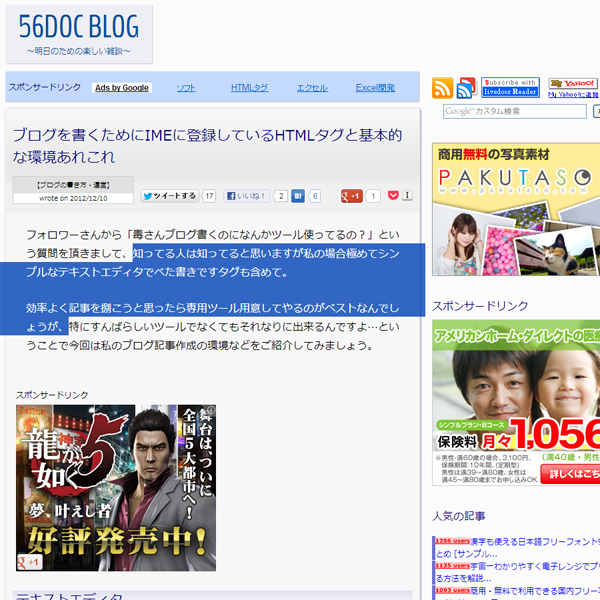
このようにblockquote引用に取り込みたいテキストを選択した状態で上記ブックマークレットを実行します。すると
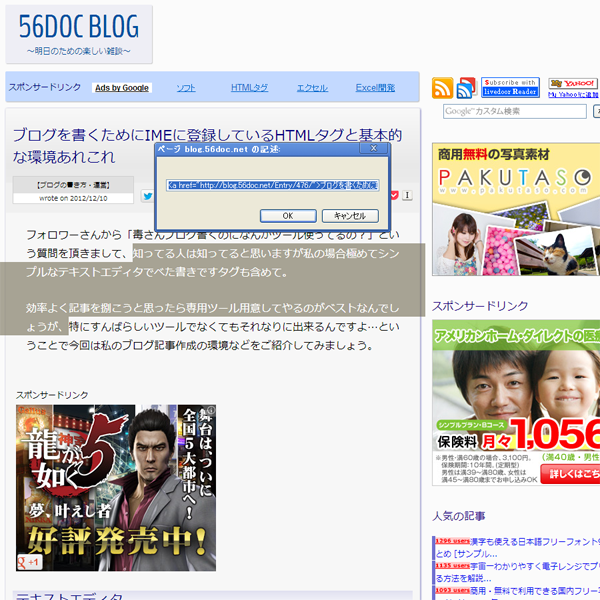
このようにダイアログが表示されてテキストエリアに諸々のHTML整形されたものが表示されますのでこれをコピペすれば引用記事書くのに楽になりますね…ということです。
取得したHTMLはこんな感じになります(読みやすいようにタグごとに改行を加えてますが実際は1行ソースとして吐かれます)。
<a href="https://blog.56doc.net/Entry/476/">ブログを書くためにIMEに登録しているHTMLタグと基本的な環境あれこれ | 56docブログ</a>
<blockquote>
<p>知ってる人は知ってると思いますが私の場合極めてシンプルなテキストエディタでべた書きですタグも含めて。</p>
<p>効率よく記事を捌こうと思ったら専用ツール用意してやるのがベストなんでしょうが、</p>
</blockquote>
JavaScript解説
以下はブックマークレットの中身的な話。不要な方は読み飛ばしてください。
最初の
IE='v'=='v';
はブラウザ判別です。IEの場合とそうでない場合の選択範囲取得処理が異なるのでまずここで判別。でIE以外のブラウザなら
selTxt = window.getSelection().toString();
このように.getSelectionで単純に選択部分を取得できる(後ろの.toStringは選択部分を文字列化してるだけ)のですが、IEだとこのままではうまくいかないです。どうやらDOM における選択範囲の仕様がW3CとMicroSoftで異なるかららしいのですが(ちょっと古いですがこの辺参照)。しょうがないのでIE用に
selTxt = document.selection.createRange().text;
if文の条件に先ほどのブラウザ判定を使って切り分けてます。でいずれの場合も取得したものをselTxtに格納。そのあとは一本道なんですが
selTxt = selTxt.replace(/[nr]+/g,'nr');
ここで選択範囲に連続した改行がある場合、それをひとつの改行にreplaceで置き換え。「/[nr]+/g」ってのは正規表現で「nr(改行コード)が1個以上ある場合にマッチ」ということです。
次に
var lastTxt = selTxt.slice(selTxt.length-1);
if(lastTxt == 'nr'){
selTxt = selTxt.slice(0,selTxt.length-2);
}
ここでは.sliceでselTxtの最後の文字を取得し、もしそれがnr(改行コード)ならばselTxtの最後の1文字を取り除いたものをselTxt自身に置き換えてます。その上で
selTxt = '<a href="' +document.URL+ '">' + document.title+ '</a><blockquote><p>' + selTxt.replace('nr','</p><p>') + '</p></blockquote>';
このようにHTMLに整形して最後にpromptで吐き出している、と言う流れです。
吐き出されたHTMLの並びは私の好みでタイトルリンク~引用(blockquote)としてますが、この辺は単に取得した情報とタグをテキスト結合してるだけなので各自好みでいじっていただけると良いと思います。一応補足しておくと
- document.URL:ドキュメントオブジェクト(現在閲覧してるページ)のURLを示すプロパティの値
- document.title:ドキュメントオブジェクトのタイトルを示すプロパティの値
- .replace(引数1,引数2):テキストオブジェクトの中の引数1というテキストを引数2というテキストに置き換えなさいよ、というメソッド
- .slice(引数1,引数2):ドキュメントオブジェクトの引数1から引数2までの間を取り出しなさいよ、というメソッド
です。.sliceの引数は文字インデックスを指定するので1文字目は0、10文字目は9とかそんな感じになります。文字数目を直接指定しちゃうと1文字ずれるので注意です。
まとめ
一応これでWebサイトからの引用文をリンク付きでそれなりにお手軽に生成できるようになった…んですが、promptで出力してコピペって一手間余計ですよね。本当はブックマークレット起動で直接クリップボードへコピーできると良いんですけど今となってはどのブラウザもJavaScriptで直接クリップボード操作はできないようになってますのでそこが残念なとこですね。
なんでJavaScriptからクリップボードにアクセスできないかと言うと、例えば何処かのWebサービスにログインするのにパスワードとかIDとかコピペでやる人いるじゃないですか。で、そういったもののデータがクリップボードに格納されててJSでそれにアクセスで来ちゃうと悪意あるサイトでその辺の情報を簡単に抜けちゃうから、ってことらしいです。まぁもっともですね。
IEだけならclipboarddata.setdataでイケるんですがクロスブラウザ対応にはなりません…まぁ無理なことだとはわかってますがどなたか上手い解法ご存知でしたら教えてくださいまし。
んじゃまた。

コメント